![[TIL] Day 9 - 범주형 변수, 웹 스크래핑](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FUokBt%2FbtrB8QgS9Uj%2FAAAAAAAAAAAAAAAAAAAAAGpa3Ew6pJlRyePMYKkvTGXekDBxwm4JXgCA_A8yC1Cc%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1785509999%26allow_ip%3D%26allow_referer%3D%26signature%3DIpMnhuqiEUPefg3jOopBl%252B6FuFY%253D)

9일차
범주형 변수 시각화
- df.unique() : 유일값 구하기
- sns.countplot(data, x) : 빈도수 시각화
- 한 가지 값만 있어도 된다.
- df[].value_count()
- 범주형 변수 하나만 있을 때 사용하기 좋다.
- 범주형 별로 카운팅을 해준다.
- 시각화를 할 때 hue 값은 3개 이하의 범주형 변수로 두는 것이 좋다.
- pd.crosstab(df[], df[])
- 컬럼을 기준으로 행의 범주화를 하여 보여준다.
- groupby(by=)
- by 값을 기준으로 그룹핑을 한다.
- groupby().mean()[]
- groupby()[].mean()
- groupby().mean()[[]]
- groupby()[[]].mean()
- df.groupby()[].agg(['mean', 'sum']) : 기술통계 값을 여러개 볼 수 있다.
- df.groupby(by=[,]).sum()[]
- 여러개의 인덱스를 볼려면 by로 묶어준다.
- df.groupby().sum()[].unstack()
- 첫번째 인덱스가 위로 올라가서 열이 된다.
- groupby() 로 묶어주고 describe() 사용 가능
- pd.pivot_table(data, index, columns, values)
- colums 를 기준으로 컬럼이 펼쳐진다.
- index 를 기준으로 행이 펼쳐진다.
- 안의 해당 값들은 values 를 기준으로 한다.
- pd.pivot_table(data, index)[[]] 이런식으로 사용해도 된다.
- aggfunc 속성을 통하여 집계 연산을 사용할 수 있다.
- sns.barplot(data, x, y, estimator)
- estimator 로 집계연산 사용 가능
- barplot 에서 검은색 막대는 신뢰구간을 의미한다.
- plt.legend(bbox_to_anchor=(1, 1)) 하면 범례를 옮길 수 있다.
- 이는 시각화 하고 나서 사용해야 한다.
- sns.scatterplot()
- 범주형 데이터에서 scatterplot은 적합하지 않다.
- sns.stripplot()
- sns.swarmplot()
- 펼쳐서 밀도를 보여주게 된다.
- size 속성을 이용해서 포인트의 크기를 조정하거나 도표 크기를 늘여서 밀도가 겹치는 문제를 해결할 수 있다.
- sns.catplot()
- 여러가지 서브 함수를 그릴 수 있다.
- “strip”, “swarm”, “box”, “violin”, “boxen”, “point”, “bar”, or “count”.
BoxPlot 이해하기
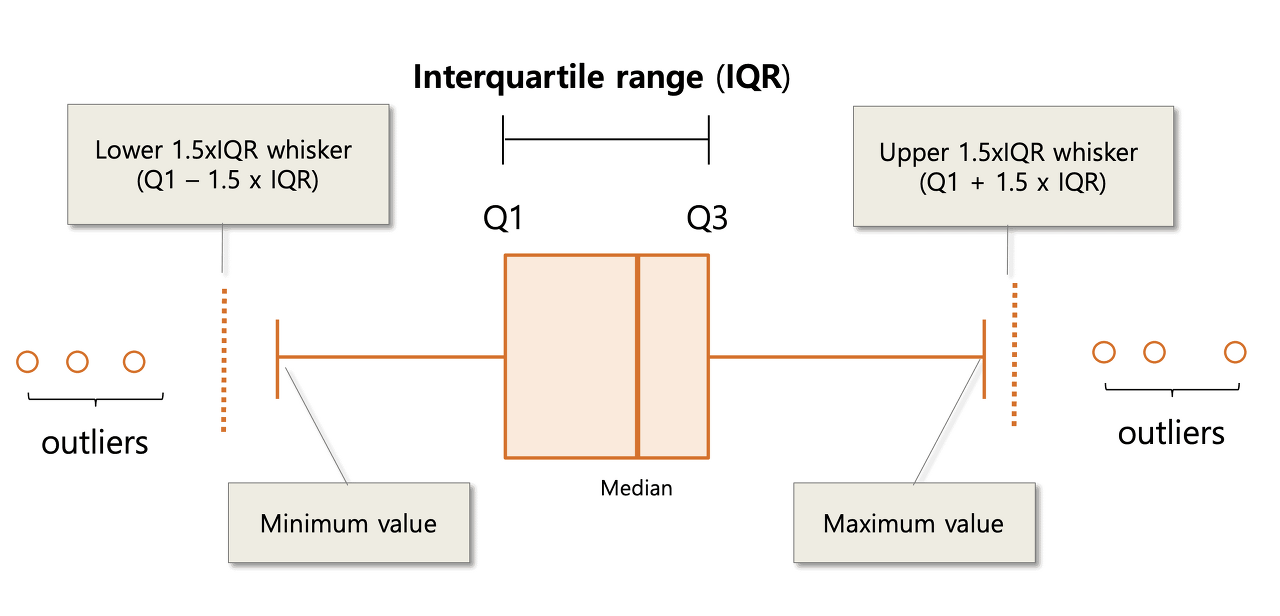
- Q1 : 하위 25%
- Q2 : 상위 50%, 중위값
- Q3 : 상위 25%, 하위 75%
- IQR (Interquartile Range)
- 신뢰구간
- Q3 - Q1
- 이상치의 끝을 나타내는 값
- OUT_MAX = Q3 + (1.5 * IQR)
- OUT_MIN = Q1 - (1.5 * IQR)
- 이러한 범위를 벗어나면 이상치로써 박스플롯에서 점으로 나타나게 된다.
- 수염의 끝은 여러가지 대안책을 나타낸다.
- 모든 데이터의 최소값과 최대값
- 여전히 1.5내의 최저 데이터 IQR 하부의 분위, 및 상부 분위수 1.5 IQR 내에 여전히 최고 데이터
- 데이터 평균 이상 표준편차 1개
- 9 백분위 수 및 91 백분위 수
- 2백분위 수 및 98 백분위 수
- sns.boxplot(data, x)
- 앤스컴 콰르텟 예시로 단점을 찾을 수 있다.
- sns.boxenplot(data, x)
- sns.violinplot(data, x)
- 밀도를 추정해서 그린다.
- 이를 사용할 것을 권장
주식 종목 데이터 모듈
- FinanceDataReader
- 주식 종목 데이터
- pip install -U finance-datareader
- pip show finance-datareader 로 설치가 되었는지 확인 가능
- import FinanceDataReader as fdr
- fdr.StockListing() 으로 데이터를 받아올 수 있다.
- KRX 로 종목 전체를 가져올 수 있음.
- pd.read_csv() 할 때 보통 한글이 들어가있는 데이터는 cp949를 따르거나 utf-8을 따라서 인코딩을 해줘야한다.
- fdr.DataReader(code, date) 를 사용해서 특정 종목의 주식 데이터를 가져올 수 있다.
뉴스 기사 수집
- f-string 을 이용하여 url 매핑
- https://finance.naver.com/item/news_news.nhn?code=005930&page=1&sm=title_entity_id.basic&clusterId=
네이버 금융
네이버 증권 종목뉴스 안내 AI(인공지능 검색기술)을 이용한 종목 관련 뉴스입니다. 관련뉴스는 자동으로 묶어 보여줍니다. 검색영역 옵션 제목 : 제목에서 종목명이 검색된 결과입니다. 내용 :
finance.naver.com
- F12 - Document - Preview 를 해서 우리가 원하는 문서 데이터가 무엇인지 미리보기로 볼 수 있다.
- pd.read_html(url, encoding) 을 이용해서 배열 값으로 데이터를 간편하게 받아올 수 있다.
- 굳이 어렵게 셀레륨 사용해서 데이터 받아올 필요 없다.
- 로그인 해야하는 사이트가 아니라면, read_html 을 사용해서 가져오자.
- table[1].colums = table[0].colums 를 이용하여 컬럼명 전체를 변경할 수 있다.
- pd.concat()
- concat(배열) 하나만 들어가면 배열을 전부 concat 한다.
- axis = 0 행을 기준으로
- axis = 1 열을 기준으로
- df.dropna(how, axis)
- how = all 모든 데이터에 결측치가 있다면
- how = any 결측치가 하나라도 있다면
- 결측치를 삭제한다.
- dropna().dropna() 하여 행/열 결측치 깔끔하게 삭제 가능
- df[~df[]] 로 뒤에 붙은 조건 데이터를 제외한 모든 데이터를 가져올 수 있다.
회고
월요일 입니다. 새로운 한 주가 시작되었습니다. 마음이 상쾌하네요.
오늘은 범주형 데이터 시각화하는 것에 대해서 배웠습니다.
또 웹 스크래핑에 대해서 간단하게 배워보았는데 확실히 강사님 코드는 항상 깔끔하고 좋은 것 같아요.
저 혼자서 데이터 전처리할 때는 좀 불필요한 코드를 많이 끼워넣었는데. 이번에도 많이 배우는 것 같습니다.
오늘은 중간중간에 너무 배고파서 쉬는시간마다 샌드위치를 먹었던 기억이 있습니다.
방금 저녁먹고 오는 길인데 지금은 배가 부르네요.
새삼스럽지만 확실히 TIL 을 적으니까 좋은 게 루틴이 만들어지는 것 같아요.
밥먹고 바로 침대에 눕기 바뻤는데, TIL 적는다고 지금 의자에 앉아있네요.
역류성 식도염도 방지하고 좋습니다.
728x90
'⛺ 𝗕𝗼𝗼𝘁 𝗖𝗮𝗺𝗽 > 멋쟁이사자처럼 AI 스쿨 6기' 카테고리의 다른 글
| [TIL] Day 11 - 웹 스크래핑 (0) | 2022.05.18 |
|---|---|
| [TIL] Day 10 - 웹 스크래핑 (0) | 2022.05.17 |
| [TIL] Day 7, 8 - 소공, SQL 기초 (0) | 2022.05.13 |
| [TIL] Day 6 - 파이썬 데이터 분석 기초 (0) | 2022.05.11 |
| [TIL] Day 4, 5 - Python 문법, EDA (0) | 2022.05.10 |